Vision Transformer(ViT)의 등장과 원리
ViT는 2020년 구글 연구팀이 발표한 논문 "An Image is Worth 16x16 Words"를 통해 세상에 알려졌습니다. 기존의 CNN이 이미지의 지역적인 특징(local feature)을 점진적으로 추출하여 전체를 이해하는 '귀납적 편향(inductive bias)'을 강하게 가지는 반면, ViT는 이미지를 여러 개의 작은 패치(patch)로 나누고, 이를 시퀀스 데이터처럼 처리하여 이미지 전체의 관계성(global context)을 한 번에 파악합니다. 자연어 처리에서 문장 속 단어들의 관계를 파악하던 셀프 어텐션(self-attention) 메커니즘을 이미지에 그대로 적용한 것입니다. 이러한 접근 방식 덕분에 ViT는 모델과 데이터의 크기가 충분히 크다면 CNN의 성능을 뛰어넘는 잠재력을 보여주었습니다.
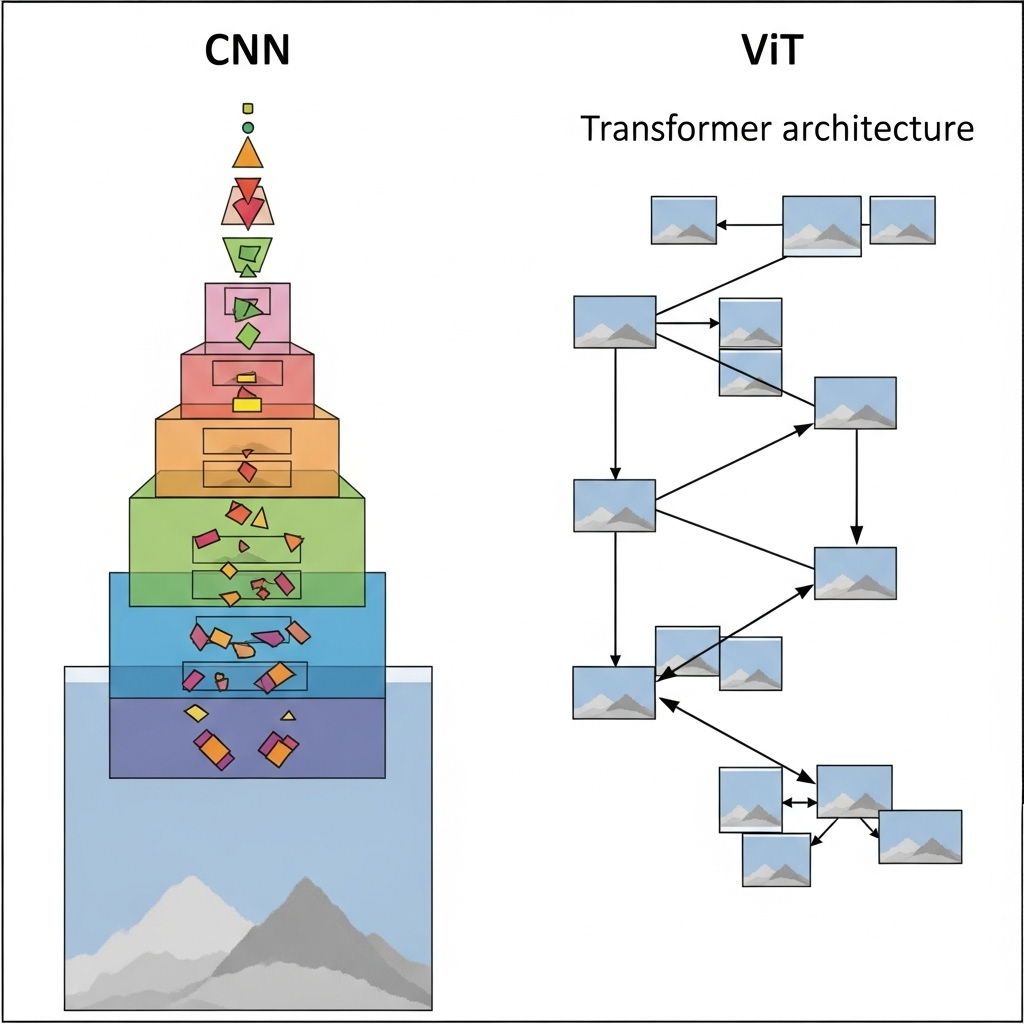
성능 대결: CNN vs. ViT, 승자는?
ViT가 처음 등장했을 때, 그 성능은 대규모 데이터셋에 대한 사전 학습(pre-training) 여부에 크게 좌우되었습니다. 구글이 자체적으로 보유한 JFT-300M과 같은 수억 장의 이미지를 사용한 사전 학습을 거쳤을 때, ViT는 ImageNet과 같은 표준 벤치마크에서 기존의 최고 성능 CNN 모델들을 능가했습니다. 이는 ViT가 방대한 데이터로부터 이미지에 대한 일반적인 지식을 학습할 수 있다면, CNN의 '지역성'이라는 제약을 넘어 더 넓은 시야로 이미지를 이해할 수 있음을 시사했습니다.
하지만 현실은 조금 더 복잡합니다. **결론부터 말하자면, 데이터의 양이 승패를 가릅니다.** 비교적 작은 데이터셋(수백만 장 이하)에서는 여전히 CNN이 더 나은 성능을 보이거나 비슷한 수준을 유지합니다. 이는 CNN이 가지고 있는 '이미지는 인접한 픽셀끼리 연관성이 높다'는 '귀납적 편향'이 적은 데이터 환경에서는 매우 효율적인 학습을 가능하게 하기 때문입니다. 반면, ViT는 이러한 사전 가정 없이 데이터로부터 모든 관계를 학습해야 하므로, 데이터가 부족하면 오히려 과적합(overfitting)에 빠지기 쉽습니다.
즉, **대규모 데이터와 컴퓨팅 자원이 확보된 환경이라면 ViT가 더 높은 성능 상한선을 보여주지만, 제한된 자원으로 특정 문제를 해결해야 하는 대다수의 산업 현장에서는 잘 설계된 CNN이 여전히 강력하고 효율적인 선택지**가 될 수 있습니다.
산업 현장에서의 ViT: 장밋빛 미래와 냉혹한 현실
ViT는 자율주행, 의료 영상 분석, 위성 이미지 해석 등 이미지의 전반적인 맥락 이해가 중요한 분야에서 큰 잠재력을 보이고 있습니다. 예를 들어, 자율주행 자동차가 도로 위의 여러 객체(자동차, 보행자, 신호등) 간의 관계를 종합적으로 파악하거나, 의료 영상에서 미세한 이상 징후와 주변 조직의 전체적인 형태를 함께 고려하여 진단하는 데 ViT의 글로벌 어텐션 능력이 강점을 가질 수 있습니다.
하지만 이러한 잠재력에도 불구하고 ViT가 산업 현장에 광범위하게 적용되기까지는 몇 가지 명확한 한계가 존재합니다.
- 막대한 데이터 및 컴퓨팅 요구량: 앞서 언급했듯, ViT의 성능은 대규모 사전 학습에 크게 의존합니다. 일반적인 기업이 구글처럼 수억 장의 데이터를 확보하고 이를 학습시킬 GPU 클러스터를 운영하는 것은 거의 불가능에 가깝습니다. 따라서 대부분의 경우 거대 IT 기업이 사전 학습한 모델을 가져와 특정 작업에 맞게 미세 조정(fine-tuning)하는 방식을 사용해야 합니다.
- 높은 연산 비용과 메모리 사용량: ViT의 셀프 어텐션은 이미지 패치 수의 제곱에 비례하여 연산량이 증가합니다. 고해상도 이미지를 처리해야 하는 경우, 이는 엄청난 컴퓨팅 비용과 메모리 부담으로 이어져 실시간 처리가 필수적인 공장 자동화나 모바일 기기 적용에 걸림돌이 될 수 있습니다.
- CNN 대비 낮은 특화성: CNN은 지난 10년간 다양한 산업 문제에 맞춰 수많은 변형 모델이 개발되었습니다. 경량화된 MobileNet부터 실시간 객체 탐지에 특화된 YOLO, 의료 영상 세분화에 강한 U-Net까지, 특정 목적에 최적화된 CNN 아키텍처가 풍부합니다. 반면 ViT는 아직 상대적으로 범용적인 구조에 머물러 있어, 특정 산업 도메인의 요구사항을 정밀하게 만족시키기 위한 연구가 더 필요한 상황입니다.
CNN의 시대는 끝나지 않았다, 다만 진화할 뿐이다
그렇다면 다시 처음의 질문으로 돌아와 "CNN의 시대는 끝났는가?"라고 묻는다면, 정답은 '**아니오**'입니다. ViT는 분명 컴퓨터 비전 분야에 새로운 패러다임을 제시한 혁신적인 기술이지만, CNN을 완전히 대체하기보다는 상호 보완적인 관계로 발전할 가능성이 높습니다.
오히려 최근 연구 동향은 CNN의 강점과 ViT의 강점을 결합하려는 **하이브리드(Hybrid) 모델**로 향하고 있습니다. 예를 들어, 초기 레이어에서는 CNN을 사용해 효율적으로 지역적인 특징을 추출하고, 후반 레이어에서는 트랜스포머를 사용해 추출된 특징들 간의 글로벌한 관계를 파악하는 방식입니다. 이를 통해 상대적으로 적은 데이터로도 높은 성능을 달성하며 연산 효율성까지 챙길 수 있습니다.
결론적으로 CNN은 죽지 않았습니다. 오히려 ViT라는 강력한 경쟁자의 등장은 CNN이 가진 고유한 강점을 다시 한번 확인시켜 주었으며, 두 아키텍처의 장점을 결합하는 새로운 방향으로의 진화를 촉진하고 있습니다. 산업 현장에서는 당분간 해결하고자 하는 문제의 특성과 보유한 데이터, 그리고 컴퓨팅 자원에 따라 CNN과 ViT를 현명하게 선택하고 조합하는 지혜가 필요할 것입니다. CNN의 시대는 끝나지 않았고, 더욱 흥미로운 '춘추전국시대'가 시작되었을 뿐입니다.